
Safety‑critical systems are at the core of TTTECH’s heritage and continue to shape its future. As intelligent, connected, and autonomous systems interact more directly with the physical world, the ability to build dependable systems under all conditions is becoming an increasingly important factor across industries.
Beyond their technical role, safety critical platforms play a crucial part in helping organizations manage growing system complexity and accelerating development cycles. Instead of engineering every system from scratch, companies can rely on proven, pre validated building blocks. This allows them to focus on their specific applications while reducing integration effort, technical risk, and time-to-market - an advantage that is essential as systems become software-defined.
From aviation and space exploration to energy, industrial automation, and off‑highway applications, this edition of CEO Talks explores how safety-critical platforms have evolved over time. Georg Kopetz CEO and co-founder of TTTECH and Christian Fidi, General Manager of TTTECH Aerospace, discuss how TTTECH defines safety, why deterministic networking and platform‑based architectures are essential, and how cross‑industry reuse helps manage complexity and enable scalable, future‑ready systems.
Defining safety at TTTECH
Before looking at architectures and technologies, it is important to clarify the foundations.
Safety is a term used across many industries, often with different meanings. How does TTTECH define safety, and why has it always been such a central topic for the company?
Georg Kopetz: At TTTECH, safety is fundamentally about integrity. It means that even if failures occur, the system behaves in a predictable and controlled manner and does not harm people, assets, or the mission. From our perspective, safety is not about preventing every failure but about ensuring the correct system response when something goes wrong.
We also clearly distinguish safety from security. Security focuses on protecting systems against external threats, while safety addresses the internal behavior of a system under fault conditions. This thinking leads directly to architectural concepts such as fail-safe, fail-silent, and fail-operational systems. Especially in safety-critical environments, fault tolerance must be built into the architecture from the very beginning.
This understanding of safety has shaped TTTECH’s work for more than two decades. From the outset, the company focused on designing architectures that make system behavior transparent, analyzable, and verifiable - even under fault conditions. This long‑term, architecture‑driven approach laid the foundation for building platforms that can be trusted across industries and certification regimes.
Christian Fidi: We typically talk about reliability levels such as 10⁻⁹, meaning one critical failure in one billion operating hours. To reach this level, systems must continue to operate even when faults occur.
In practice, this means that functions must not be affected by single or multiple failures. Flight control systems are a good example: if a sensor fails, the pilot must not notice any degradation in functionality. This is why fail-operational behavior is a fundamental requirement in the systems we design and support. These requirements strongly influence how architectures are designed, validated, and certified.
Why safety-critical systems depend on distributed architectures and networking
After defining safety in terms of fault tolerance and fail operational behavior, why does TTTECH place such strong emphasis on distributed architectures and networking?
Georg Kopetz: If you look at the origin of TTTECH, we started with networks and distributed architectures. When we talk about safety critical systems and very high dependability levels such as 10⁻⁹, it becomes clear that a single system is not sufficient.
With a monolithic system, if something goes wrong at the physical location where the computer is placed, the entire system goes down. Distributed architectures change that. They allow safety to be spread across multiple computing units and physical locations. In this context, the network is not just a connector, it becomes a core part of the safety concept.
Christian Fidi: From a reliability perspective, this is essential. Single computer units have a certain probability of failure, but they will never reach these reliability numbers on their own. To reach 10⁻⁹, redundancy is required.
Once you introduce redundant units, you need a way to connect them. That connection must meet strict requirements so that the overall system architecture can operate reliably. This is only possible with a network that connects computers, sensors, and actuators in a controlled and predictable way.
From a customer perspective, this architectural choice is critical. By moving key safety mechanisms into a deterministic and fully verified network layer, overall system complexity becomes easier to control. This simplifies system integration and validation, especially as more computing units and functions are added over time.
Networking as the basis for fault-tolerant behavior
Once distributed architectures are in place, how do networks practically support fault tolerance in safety critical systems?
Georg Kopetz: In practice, fault tolerance always comes down to comparison. If you want to implement fault‑tolerant or voting algorithms, you need to read data from different sensors and different computers and then compare this data.
To be able to compare information coming from physically separated units, the network enables fault‑tolerant mechanisms such as comparison and voting across distributed components. This is where we have always been positioned: networking enables the distribution of safety across a system instead of concentrating it in one place.
Christian Fidi: From a system point of view, the network must reliably connect all relevant elements - computers, sensors, and actuators. Especially in highly reliable systems such as flight control systems, functions cannot be affected by failures.
The network ensures that redundant components can exchange data in a controlled way, allowing the system to continue operating exactly as designed even if individual elements fail.
Designing a safety architecture
Networking is a core pillar of safety‑critical systems, but clearly it is not sufficient on its own. How do you approach the design of a complete safety architecture?
Georg Kopetz: As we continued to develop safety‑critical networks, it became very clear to us that a safe system requires much more than just networking. At some point, the focus naturally expands to the overall safety architecture.
When you start thinking about safety at system level, you need to consider how all elements work together: computing units, networking, sensors, actuators, and the software layers on top. Only if these elements are aligned can systems remain safe and operable under all conditions.
Christian Fidi: Typically, the starting point is always the overall system architecture. You identify the safety‑critical functions and then look at how their data is used across the system, often even beyond a single system boundary. This leads to what we describe as systems of systems.
The core system must therefore remain fully under control, while still offering clearly defined interfaces that allow new functions to be added on top. This platform‑oriented approach allows systems to evolve without compromising their established safety properties. New functions can be integrated incrementally, while the core architecture remains stable - an important prerequisite for certification, long‑term operation, and system upgrades over decades.
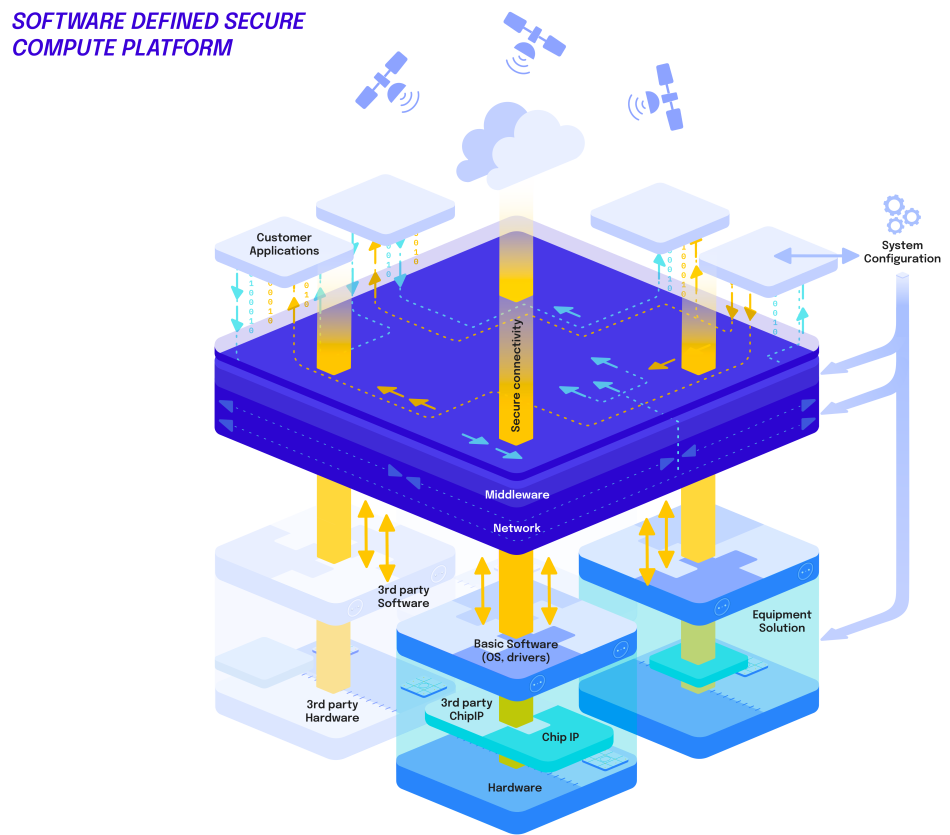
What does this mean in terms of concrete system elements?
Christian Fidi: Networking is one important element, but there is also redundant computing. You need a very clear structure across different software levels, across computing nodes, and across the communication paths connecting them.
From a design perspective, this also means consciously placing complexity where it can be controlled most effectively. By implementing key safety mechanisms in a verified network layer, systems avoid pushing excessive complexity into application software, simplifying integration, validation, and long term maintenance.
Classical control concepts still apply: sensors, computing units, and actuators must operate reliably and in parallel. The entire control chain must function in a consistent and predictable way.
Georg Kopetz: At the same time, these systems are no longer isolated. More additional functions are integrated into the same system - for example camera systems and other data‑intensive components. This significantly increases the demands placed on the underlying safety architecture and makes a platform‑oriented approach essential.
Rising complexity in modern safety systems
How does this evolution impact systems complexity?
Christian Fidi: We clearly see a shift from systems based on discrete values toward systems processing complex data streams. Instead of working with individual signals such as speed or position, systems now integrate camera data, lidar signals, and other sensor inputs.
These data streams are fused and used for decision‑making and operation. In some cases, decisions are no longer based purely on predefined logic, but on learned behavior - for example neural‑network‑based systems. This results in a significant increase in system complexity.
Georg Kopetz: This development underlines why a structured and well‑defined architecture is so important. As software size and system complexity grow, it becomes increasingly difficult to manage validation, certification, and long‑term maintainability without a stable architectural foundation.
Without such a foundation, effort, risk, and engineering cost would increase at a pace that is no longer sustainable for complex, long‑lifecycle systems.
Functional safety and fail‑operational systems
How do functional safety and fail‑operational concepts shape TTTECH’s work in aerospace, space, and defense?
Georg Kopetz: Aerospace and space have always been leading domains for safety‑critical systems, because failures have an immediate and severe impact when systems are flying or operating in space. From the beginning, functional safety and fail‑operational behavior were essential properties of these systems. They define how systems must continue to behave correctly even when faults occur.
Christian Fidi: At TTTECH, we typically operate at the highest safety levels. In aerospace, this includes highly safety‑critical systems such as flight control systems, landing gear systems, or power distribution systems. These systems must not fail. They are fail‑operational, meaning that even if one or multiple faults occur, the system continues to operate without degrading its functionality. If a sensor fails in a flight control system, the pilot must not notice any difference.
At the same time, many other systems use the data produced by safety‑critical systems. Some of these become mission‑critical systems. Even if they are not directly safety‑critical for people, they are still essential for mission success and commercial operation, for example video systems or cabin‑related applications. This adds further complexity to the overall system.
Georg Kopetz: What we have seen over the last twenty years is a strong proliferation of safety‑critical and mission‑critical systems across many different domains. Wherever cyber‑physical systems interact with humans, safety becomes a key property of computing systems.
This development is one of the reasons why TTTECH expanded its safety‑critical computing and networking expertise into multiple vertical markets.
Scaling safety across industries and vertical markets
TTTECH applies safety‑critical technologies across many different industries. How do energy, wind power, nuclear, and other industrial markets relate to your core expertise from aerospace?
Georg Kopetz: Over the last few years, we have expanded far beyond aerospace and space. One area where this becomes very visible is energy production. We have been active in wind power for quite some time, and more recently also in nuclear energy projects.
What is interesting is that, although these industries are very different in their applications, they share many underlying principles when it comes to safety‑critical systems.
Christian Fidi: We see a strong convergence across industries. Automotive, aerospace, and industrial domains are increasingly influenced by similar standards and approaches. There is a lot of learning across these industries, and we are actively involved in cross‑industry standardization activities.
Many of the technologies we developed in the past are now reflected in these standards. This is very positive, although it also introduces complexity. That complexity needs to be managed at the right level.
Our approach is to focus on core technology and core products. The core software and the core IP can remain largely unchanged across different markets. On top of that, we adapt products to specific requirements, for example different hardware or environmental conditions. This allows us to reuse proven building blocks while still addressing the needs of each industry.
Georg Kopetz: This cross‑industry approach is a clear advantage for us. Every vertical adds specific expertise and experience. By working across aerospace, energy, industrial, and other markets, we continuously advance our technology and product base and strengthen our core safety‑critical platforms.
Core building blocks and reuse across verticals
Across all these different industries, what are the core elements that remain the same and can be reused?
Christian Fidi: One of the core elements we have developed is the network. This core network allows different ways of structuring system architectures. You can configure different levels of redundancy and reliability - for example very high redundancy for aerospace, but also other configurations for automotive or industrial applications.
By combining these building blocks, it becomes possible to move very quickly from mature, proven components to complete system‑level solutions and products. This core has been central to how we approach different markets.
We also see these building blocks increasingly reflected in standards. There is convergence across industries, and these core elements are becoming common foundations. This confirms our belief that focusing on core technology and reusable components is the right approach.
Georg Kopetz: Another important aspect that benefits all industries is the distribution of intelligence. Systems today are much more distributed than they were in the past. Safety‑critical networking and platforms grow in importance as systems become more distributed. This also connects to topics such as cybersecurity, verification tools, and safety computing across multiple processing units. Verification plays a crucial role in these architectures. Safety-critical systems rely on mechanisms that continuously compare inputs and outputs across redundant processing units, ensuring that deviations are detected and handled deterministically. Many of these elements are driven by developments in the chip industry and then applied across different verticals.
While standards and certification approaches may differ between industries, the underlying principles are very similar. At the level of architectures and data processing, the same core building blocks can be leveraged across multiple domains.
Platformization and concrete deployments
When looking at your concrete projects across industries, how does this idea of a common safety‑critical platform show up in real deployments?
Georg Kopetz: If you look at the architectures we have deployed over the last decade, for example with Vestas in wind power, with Honeywell in the Anthem cockpit, or more recently in the NASA Artemis missions, you see the same architectural principles applied across very different applications.
In all these cases, we are using similar building blocks and combining safety‑critical networking, computing, and system architecture into an integrated platform.
Christian Fidi: The network is always a core element. We often refer to it as the nervous system of the overall architecture. Today, this is largely Ethernet‑based, starting at one gigabit/s and moving toward higher speeds such as ten gigabit and beyond.
What stays consistent is the idea of a digital, safety‑critical backbone that interconnects the different computing units. On top of that, we connect systems in a way that keeps complexity manageable, especially as the systems scale.
Another important aspect is how computing is connected and how complexity is distributed. We see a strong increase in distributed computing, especially when you look at the number of lines of code in modern aerospace and defense systems. This makes a platform approach essential. It allows us to manage complexity while integrating additional topics such as cybersecurity or preparing systems for future extensions.
Georg Kopetz: What is important for us is that these platforms can be reused across different verticals. Even though the applications differ, the underlying architecture remains very similar.
This is where platformization becomes tangible: customers can rely on pre‑validated building blocks that have already been deployed in demanding real‑world environments and then build their specific applications on top.
For customers, this reduces the effort required to integrate new functions and lowers program risk, as core elements have already been validated in comparable system contexts.
Evolving the platform - High-speed networks and system integration
How does the TTTECH platform evolve to support increasing bandwidth requirements and more complex system use cases?
Georg Kopetz: When we talk about platformization at TTTECH, we really mean a systems approach. We see TTTECH as a platform company providing safety‑critical processing, safety‑critical networking, verification tools, architectural support, and cybersecurity hardening as one integrated platform. For our customers, this is important because they can reuse pre‑validated and pre‑tested platform building blocks and then build their applications on top.
Christian Fidi: We have always referred to this as a core avionics or core platform. This core consists of the computers, the network, and the nodes that bring in data from sensors and actuators. On top of that, there is the related middleware software, which allows applications to be integrated. We developed this platform initially for gigabit Ethernet, fully safety‑certified for civil aviation, as well as for space standards, including NASA and European space requirements.
This development is now being extended to higher speeds. We are moving toward ten‑gigabit and forty‑gigabit per link, with total system bandwidths in the range of 300 to 400 gigabit. This has been one of our major development focuses over the past years, and we are currently in the process of bringing these products to market.
What is important is that the same network supports not only safety‑critical functions, but also mission‑critical functions. This is relevant in defense and space applications, where different experiments or mission data can be combined with safety‑critical control functions within one system.
Georg Kopetz: If we can run different types of functions on the same network, that creates a significant advantage at system level. It allows savings in size, weight, and power, which is essential for aerospace and space systems.
Determinism and time‑triggered communication
Why is time‑triggered communication used in safety‑critical systems, for example in the Artemis II mission?
Georg Kopetz: With Artemis II, Time‑Triggered Gigabit Ethernet was used successfully. We introduced time‑triggered concepts into Ethernet and standardized them, for example in TSN and Time‑Triggered Ethernet.
The reason is simple: safety and timing are closely connected. Safety‑critical systems need deterministic behaviour, and determinism requires time.
Christian Fidi: This is very visible in control systems. Data is captured by sensors, processed by computers, and sent to actuators. For these control loops, timing behaviour is critical.
You need to know exactly how long data travels from the sensor to the computer and to the actuator. These systems run periodically.
To do this, the system needs a notion of time. Sensors, computing units, and actuators must know what time it is.
This synchronization must not depend on a single node. If one node fails, synchronization still has to work and remain accurate. This is why we implemented synchronization first with the time‑triggered protocol and later with Time‑Triggered Ethernet.
With time‑triggered communication, it is defined when messages are sent and when they are received. This is essential for fail‑operational systems and redundant control systems.
Georg Kopetz: Time gives data a clear meaning. We know when data was sensed and when it was received.
This is very important for safety‑critical systems. Many fault‑tolerant algorithms depend on timing. Without a global guarantee of time, fault tolerance becomes very difficult.
Mixed criticality and partitioning
How do you ensure that non‑safety‑critical data does not interfere with safety‑critical functions in the same system?
Christian Fidi: There are different mechanisms in the network to achieve this. One is the use of priorities, where traffic has different levels of importance. Another key mechanism is partitioning. We separate memory in all units—in switches and end systems—so that traffic does not interfere. This allows us to fully partition traffic on the network.
With this approach, safety‑critical data and non‑safety‑critical data can operate on the same physical media, on the same cable. This brings significant advantages, for example by reducing the weight of the overall system.
Georg Kopetz: We often explain this as bandwidth partitioning. Similar to memory partitioning on the computing side, bandwidth partitioning protects access to the network.
Only within defined time windows is certain communication allowed to take place. Other data does not even get access to the medium. This protection is enforced in the switches, ensuring that safety‑critical communication is not disturbed.
Christian Fidi: Today, many systems assume that increasing bandwidth alone will solve these problems. But even with ten‑gigabit networks, available bandwidth can fill up quickly and networks become very complex.
Ensuring that safety‑critical data still operates correctly next to other data becomes increasingly difficult.
Georg Kopetz: Especially in switched buffered networks, overflows can occur. In non‑time‑triggered architectures, this makes it very difficult to guarantee that safety‑critical bandwidth is preserved.
MotionAI as an extension to safety‑critical platforms
How does the MotionAI development fit into TTTECH’s safety‑critical platforms, and how transferable is this technology from off‑highway to aerospace and space applications?
Georg Kopetz: Before moving to the next topic, I would like to touch on MotionAI. We are combining high‑performance computing technology from the automotive industry with highly qualified silicon that supports safety and security. The goal is to bring safety and security to machine‑learning and AI computing. We are doing this initially for the off‑highway industry, with launch customers in autonomy. The key question is how this can be transferred into safety‑critical systems in aeronautics, space, and defense.
Christian Fidi: The basis is the network. If you have a network that allows you to connect such units to a safety‑critical system, the integration becomes manageable. If you add these units as building blocks, redundancy management and safety assessment become much simpler than building everything from scratch. The properties of the core system remain stable - a crucial prerequisite for safety‑critical architectures.
Georg Kopetz: So even if such an AI unit itself is not at the highest safety level, connecting it to a safety‑critical network ensures that the safety‑critical paths continue to operate as intended.
Christian Fidi: Exactly. This is what we refer to as composability. Over the years, we have implemented this concept in our tools, allowing systems to be extended without changing their behaviour.
We can configure and verify such extensions and prove that they do not interfere with the existing safety properties. From a technical perspective, there is strong potential for aerospace, especially for autonomy functions. Examples include autonomous taxiing or space applications such as moon landings, where systems must make decisions very quickly based on sensor data.
While hardware requirements differ significantly between off‑highway and aerospace, there is a lot of reuse on the software side. Verified functions and structured software architectures provide a strong basis for that transfer.
Outlook – Physical AI, robotics, and space momentum
How do you see the momentum of physical or embodied AI and robotics developing, especially in space and defense applications?
Georg Kopetz: We believe that systems and platforms will become even more important in the age of robotics and physical AI. These applications require a combination of safety‑relevant networking, computing, and verified system software.
In space exploration, we clearly see this momentum increasing. After Artemis II, the focus is shifting toward operations around the Moon and toward establishing a lunar base. These environments require a high degree of autonomous operation.
Christian Fidi: In my current portfolio, two markets are moving particularly fast: space and defense. On the space side, recent changes in the Artemis program place much more emphasis on lunar operations and on activities at a lunar base.
This creates a strong demand for platforms - pre‑configured systems that allow projects to move at the required speed. The same applies to other space applications, such as in‑orbit operations and satellite servicing, where robotic systems play an important role.
Georg Kopetz: A lunar base will effectively act as a test bed for autonomous technologies. It will require a high level of autonomous operation, and this will further increase the demand for safety‑critical systems.
In defense, we also see strong momentum, particularly for dual‑use technologies. Customers value the ability to use commercially developed technologies in military contexts, especially for mission‑critical systems where speed of deployment and reliability are essential.
Christian Fidi: Another important factor is scale. By using the same products across different markets, we achieve higher volumes. This makes it easier to maintain and evolve systems compared to solutions that are developed for very small quantities in space or defense only.
Georg Kopetz: Overall, we expect a significant increase in safety‑critical systems - on the ground, in the air, and in space. The combination of autonomy, robotics, and safety‑critical platforms will continue to drive this development.
This edition of CEO Talks explored how safety‑critical systems, deterministic communication, and platform‑based architectures are evolving across industries. From aerospace to industrial and autonomous applications, the discussion highlighted how core safety principles remain fundamental - even as system complexity, performance demands, and autonomy continue to increase.
As technologies converge and new use cases emerge, safety‑critical platforms play a central role in enabling reliable, scalable, and future‑ready systems across domains.
We look forward to continuing this conversation in future editions of CEO Talks.